유전 알고리즘(GA)과 유전 프로그래밍(GP)은 흥미로운 연구 분야입니다.GA/GP를 사용하고 해결한 특정 문제와 직접 롤링하지 않을 경우 사용한 라이브러리/체제에 대해서 알고 싶습니다.질문:GA/GP를 사용하고 어떤 문제를 해결했습니다?어느 라이브러리/체제를 사용했습니까?나는 직접적인 경험을 찾고 있으므로 해당 사항이 없다면 대답하지 마세요.숙제가 중요한지 모르겠다.공부하는 동안 우리는 여행 하는 외판원 문제를 해결하기 위해서 자체 프로그램을 실시했습니다.아이디어는 다양한 기준(문제 매핑의 어려움, 성능 등)을 비교하는 것이며, Simulated annealing 같은 다른 기술도 사용했습니다.그것은 잘 기능했지만”재생”스텝을 제대로 실행하는 방법을 이해하기에는 시간이 걸렸습니다. 당면 문제를 유전 프로그래밍에 적합한 것으로 모델링 하는 것이 가장 어려운 부분이었습니다…우리도 뉴럴 네트워크 등을 다루어 온 것에서 흥미로운 과정이었습니다.누군가가 “프로덕션”코드에서 이런 프로그래밍을 사용했는지 궁금합니다.
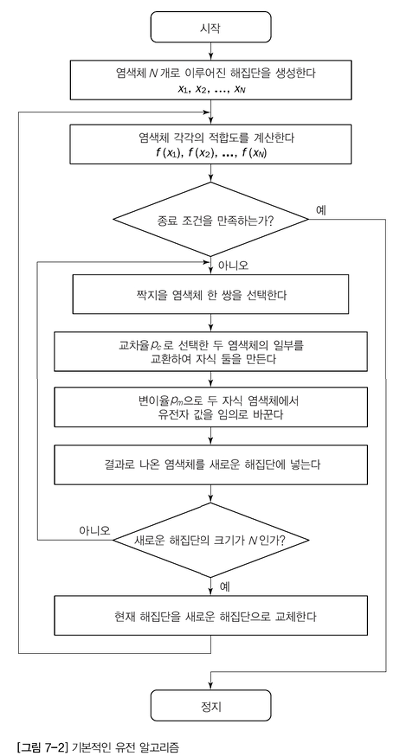
유전 알고리즘(GA)과 유전 프로그래밍(GP)은 흥미로운 연구 분야입니다.GA/GP를 사용하여 해결한 특정 문제와 직접 롤링하지 않을 경우 사용한 라이브러리/프레임워크에 대해 알고 싶습니다.질문: GA/GP를 사용하여 어떤 문제를 해결했습니까?어떤 라이브러리/프레임워크를 사용했습니까?나는 직접적인 경험을 찾고 있으니 해당 사항이 없으면 대답하지 마세요.숙제가 중요한지 모르겠어.공부하는 동안 우리는 여행하는 세일즈맨의 문제를 해결하기 위해 독자적인 프로그램을 진행했습니다.아이디어는 다양한 기준(문제 매핑의 어려움, 성능 등)을 비교하는 것이며 Simulated annealing과 같은 다른 기술도 사용했습니다.그것은 꽤 잘 작동했지만, ‘재생’ 단계를 올바르게 실행하는 방법을 이해하는 데 시간이 걸렸습니다. 당면한 문제를 유전 프로그래밍에 적합한 것으로 모델링하는 것이 가장 어려운 부분이었습니다… 저희도 신경망 등을 다뤄왔기 때문에 흥미로운 프로세스였습니다.누군가가 ‘프로덕션’ 코드에서 이런 종류의 프로그래밍을 사용했는지 알고 싶습니다.
숙제가 아닙니다.프로 프로그래머로서의 첫 직장(1995)는 S&P500선물을 위한 유전자 알고리즘 기반 자동 거래 시스템을 작성하는 것이었습니다. 애플리케이션은 Visual Basic 3[!]에서 작성되고 VB3에는 클래스도 않아서 그 당시는 어떻게 작업을 했는지 모르겠어요.애플리케이션은 무작위로 생성된 고정 길이 문자열(“유전자”부분)의 인구 집단에서 시작되면서 각 문자열은 특정 주문뿐만 아니라 S&P500선물을 분 단위 가격 데이터의 특정 형상에 대응합니다. (구입 또는 판매)및 손절 및 손절 금액. 각 문자열(또는”유전자”)는 3년간의 과거 데이터를 통해서 평가된 수익 실적을 가지고 있습니다. 지정된 “쉐이프”가 과거의 데이터와 일치할 때마다 그 인수 또는 매수를 가정하고 거래 결과를 평가했습니다. 나는 각 유전자가 고정된 금액으로 시작되고 잠재적으로 파산하고 유전자 풀로부터 완전히 제거될 가능성이 있다는 경고를 추가했습니다.개체군의 각 평가 후 생존자는 무작위로 교배당한(두 부모의 비트만을 혼합하여)부모로 선정되는 유전자의 가능성은 생산된 이익에 비례합니다. 또 포인트 돌연변이 가능성을 추가하고, 작은 즐거움을 더했습니다. 수백 세대의 세대가 지난 뒤 저는 사망/파손의 기회 없이 5000달러를 평균 약 10000달러에 교환할 수 있는 유전자 집단을 갖게 되었습니다.(물론 역사적 데이터에서).아쉽게도 저는 이 시스템을 라이브로 사용할 기회가 없었습니다. 제 상사가 전통적인 방식으로 거래하는 3달도 안 돼거의$100,000에 가까운 손실을 입어 프로젝트를 계속하겠다는 의지를 잃었기 때문입니다. 뒤돌아보면, 시스템은 엄청난 이익을 올렸다고 생각합니다. 내가 꼭 옳은 일을 하고 있었기 때문이 아니라 내가 생산한 유전자의 수가 우연히 매수 주문(매도 주문과 반대)에서 약 5배 정도로 편향된 때문입니다. 1비율. 그리고 우리가 20/20 되돌아보면, 아시다 시피, 시장은 1995년 이후 조금 상승했습니다.

숙제가 아닙니다.프로 프로그래머로서의 첫 번째 일(1995)은 S&P500 선물을 위한 유전자 알고리즘 기반 자동 거래 시스템을 만드는 것이었습니다. 애플리케이션은 Visual Basic 3 [!]로 작성되었고 VB3에는 클래스도 없었기 때문에 그 당시에는 어떻게 작업을 했는지 알 수 없습니다.애플리케이션은 랜덤으로 생성된 고정 긴 문자열(‘유전자’ 부분)의 모집단으로 시작하며, 각 문자열은 특정 주문뿐만 아니라 S&P500 선물의 분단위 가격 데이터의 특정 형상에 대응합니다. (구매 또는 판매) 및 손절매 및 손절매 금액. 각 문자열(또는 ‘유전자’)은 3년간의 과거 데이터를 통해 평가된 수익 실적을 가지고 있습니다. 지정된 ‘쉐이프’가 과거 데이터와 일치할 때마다 그 매수 또는 매도 주문을 가정하여 거래 결과를 평가했습니다. 나는 각 유전자가 고정된 금액으로 시작하여 잠재적으로 파산하고 유전자 풀에서 완전히 제거될 수 있다는 경고를 추가했습니다.개체군의 각 평가 후 생존자는 무작위로 교배되며(두 부모의 비트만을 혼합하여) 부모에게 선택되는 유전자의 가능성은 생산된 이익에 비례합니다. 또한 포인트 돌연변이 가능성을 추가하여 약간의 즐거움을 더했습니다. 수백 세대가 지난 후, 저는 사망/파손의 기회 없이 10000달러를 평균 약 5000달러로 교환할 수 있는 유전자 집단을 갖게 되었습니다.(물론 역사적 데이터로부터)유감스럽게도 저는 이 시스템을 라이브로 사용할 기회가 없었습니다. 제 상사가 전통적인 방식으로 거래하기 3개월도 안 돼 거의 $100,000에 가까운 손실을 입었고 프로젝트를 계속할 의지를 잃었기 때문입니다. 돌이켜보면 시스템은 엄청난 이익을 올렸다고 생각합니다. 내가 꼭 옳은 일을 해서가 아니라 내가 생산한 유전자 수가 우연히 인수 주문(매도 주문과 반대)에서 약 5배 정도 편향됐기 때문입니다. 1 비율. 그리고 우리가 20/20 돌이켜보면 아시다시피 시장은 1995년 이후로 약간 상승했습니다.

숙제가 아닙니다.프로 프로그래머로서의 첫 번째 일(1995)은 S&P500 선물을 위한 유전자 알고리즘 기반 자동 거래 시스템을 만드는 것이었습니다. 애플리케이션은 Visual Basic 3 [!]로 작성되었고 VB3에는 클래스도 없었기 때문에 그 당시에는 어떻게 작업을 했는지 알 수 없습니다.애플리케이션은 랜덤으로 생성된 고정 긴 문자열(‘유전자’ 부분)의 모집단으로 시작하며, 각 문자열은 특정 주문뿐만 아니라 S&P500 선물의 분단위 가격 데이터의 특정 형상에 대응합니다. (구매 또는 판매) 및 손절매 및 손절매 금액. 각 문자열(또는 ‘유전자’)은 3년간의 과거 데이터를 통해 평가된 수익 실적을 가지고 있습니다. 지정된 ‘쉐이프’가 과거 데이터와 일치할 때마다 그 매수 또는 매도 주문을 가정하여 거래 결과를 평가했습니다. 나는 각 유전자가 고정된 금액으로 시작하여 잠재적으로 파산하고 유전자 풀에서 완전히 제거될 수 있다는 경고를 추가했습니다.개체군의 각 평가 후 생존자는 무작위로 교배되며(두 부모의 비트만을 혼합하여) 부모에게 선택되는 유전자의 가능성은 생산된 이익에 비례합니다. 또한 포인트 돌연변이 가능성을 추가하여 약간의 즐거움을 더했습니다. 수백 세대가 지난 후, 저는 사망/파손의 기회 없이 10000달러를 평균 약 5000달러로 교환할 수 있는 유전자 집단을 갖게 되었습니다.(물론 역사적 데이터로부터)유감스럽게도 저는 이 시스템을 라이브로 사용할 기회가 없었습니다. 제 상사가 전통적인 방식으로 거래하기 3개월도 안 돼 거의 $100,000에 가까운 손실을 입었고 프로젝트를 계속할 의지를 잃었기 때문입니다. 돌이켜보면 시스템은 엄청난 이익을 올렸다고 생각합니다. 내가 꼭 옳은 일을 해서가 아니라 내가 생산한 유전자 수가 우연히 인수 주문(매도 주문과 반대)에서 약 5배 정도 편향됐기 때문입니다. 1 비율. 그리고 우리가 20/20 돌이켜보면 아시다시피 시장은 1995년 이후로 약간 상승했습니다.Traveling Salesman및 Roger Alsing의 Mona Lisa프로그램의 변형 같은 몇가지 일반적인 문제뿐만 아니라 진화적인 Sudoku 설 바도 작성했습니다. 다른 사람의 아이디어). Sudokus를 해결하기 위한 보다 안정된 알고리즘이 있는데 진화적 접근법은 잘 기능합니다.요 며칠 나는 Reddit에서 이 기사를 본 뒤 포커를 위한 “콜드 덱”을 찾기 위한 진화적 프로그램에서 놀았습니다. 아직 만족할 수 없으나 개선할 수 있다고 생각합니다.진화 알고리즘에 사용하는 나만의 체제가 있습니다.우선 Jonathan Koza(amazon)”Genetic Programming”은 많은 예가 한 유전 및 진화 알고리즘/프로그래밍 기술에 관한 책입니다. 나는 그것을 확인하는 게 좋겠어요.자신의 유전 알고리즘의 사용에 관해서 나는 개체 수집/파괴 시나리오(실제 목적은 지뢰원을 청소하는 것이었을 가능성이 있다)때문에 떼 알고리즘을 발전시키기 위해서(자가 재배의)유전 알고리즘을 사용했습니다. 여기에 논문에 대한 링크가 있습니다. 내가 한 것에서 가장 흥미로운 부분은 다단계적 적합도 함숬는데 이제는 단순 적합도 함수가 모집단 구성원을 충분히 구별할 수 있는 유전 알고리즘에 대한 충분한 정보를 제공하지 않았기 때문에 필요했습니다.먼저 Jonathan Koza(amazon)의 ‘Genetic Programming’은 많은 예가 있는 유전 및 진화 알고리즘/프로그래밍 기술에 관한 책입니다. 나는 그것을 확인하는 것이 좋습니다.나 자신의 유전 알고리즘 사용에 관해 나는 개체 수집/파괴 시나리오(실제 목적은 지뢰밭을 청소하는 것이었을 가능성이 있다)를 위해 무리 알고리즘을 발전시키기 위해 (자가 재배한) 유전 알고리즘을 사용했습니다. 여기 논문에 대한 링크가 있습니다. 내가 한 일에서 가장 흥미로운 부분은 다단계적 적합도 함수였는데, 이는 단순 적합도 함수가 모집단 구성원을 충분히 구별할 수 있는 유전 알고리즘에 대한 충분한 정보를 제공하지 않았기 때문에 필요했습니다.한번은 유전 프로그래밍에 근거한 바둑 게임용 컴퓨터 플레이어를 만들겠다고 했습니다. 각 프로그램은 일련의 이동에 대한 평가 기능으로 처리됩니다. 제작된 프로그램은 매우 작은 3 x 4보드라도 별로였습니다.Perl을 사용하고 모든 것을 직접 코딩했습니다. 나는 오늘 다른 일을 할 작정이다.한 번은 유전 프로그래밍에 기반한 바둑 게임용 컴퓨터 플레이어를 만들려고 했습니다. 각 프로그램은 일련의 이동에 대한 평가 기능으로 처리됩니다. 제작된 프로그램은 아주 작은 3×4 보드로도 별로 좋지 않았습니다.Perl을 사용하여 모든 것을 직접 코딩했습니다. 나는 오늘 다른 일을 할 거야.The Blind Watchmaker를 읽은 후 나는 Dawkins가 시간이 갈수록 진화할 수 있는 유기체 모델을 만들기 위해서 개발했다고 말한 파스칼 프로그램에 관심을 갖게 되었습니다. 저는 Swarm을 사용하고 자신의 글을 작성 할수록 흥미가 있었습니다. 나는 그가 만든 모든 멋진 동물 그래픽을 만들지 않았지만 나의 “염색체”은 유기체의 생존 능력에 영향을 미치는 특성을 제어했습니다. 그들은 단순한 세계에 살면서 서로와 환경에 대항해 싸울 수 있었습니다.유기체는 부분적으로 우연으로 살거나 사망했습니다만, 또 지역 환경에 얼마나 효과적으로 적응하거나 영양분을 얼마나 잘 섭취했는지, 얼마나 성공적으로 번식했는지에 의해서 다릅니다. 재미 있었지만, 아내에게 내가 괴짜라는 증거이기도 했습니다.The Blind Watchmaker를 읽은 후, 저는 Dawkins가 시간이 지남에 따라 진화할 수 있는 유기체 모델을 만들기 위해 개발했다고 말한 파스칼 프로그램에 관심을 갖게 되었습니다. 나는 Swarm을 사용해서 내 글을 작성할 정도로 흥미가 있었어요. 나는 그가 만든 모든 멋진 동물 그래픽을 만들지 않았지만, 나의 ‘염색체’는 유기체의 생존 능력에 영향을 미치는 특성을 제어했습니다. 그들은 단순한 세계에 살면서 서로 환경에 맞서 싸울 수 있었습니다.유기체는 부분적으로 우연에 의해 살거나 사망하기도 했지만 또 지역 환경에 얼마나 효과적으로 적응했는지, 영양분을 얼마나 잘 섭취했는지, 얼마나 성공적으로 번식했는지에 따라 달라집니다. 재미있었지만 아내에게 제가 괴짜라는 증거이기도 했어요.몇주 전 저는 그래프 레이아웃 문제를 해결하기 위해서 유전 알고리즘을 사용하여 SO에 대한 솔루션을 제안했습니다. 이는 제약된 최적화 문제의 예입니다.또, 머신 러닝 영역에서 C/C++에서 GA기반의 분류 규정 프레임워크를 처음부터 구현했습니다.또 유명한 역전파 알고리즘을 사용하는 대신 인공 뉴럴 네트워크(ANN)훈련을 위한 샘플 프로젝트에서 GA을 사용했습니다.또 대학원 연구의 일환으로서 EM기반의 Baum-Welch알고리즘(c/c++에서 다시)에 대한 추가 접근으로서 Hidden Markov Models교육에 GA을 사용했습니다.몇 주 전, 나는 그래프 레이아웃 문제를 해결하기 위해 유전 알고리즘을 사용하여 SO에 대한 솔루션을 제안했습니다. 이것은 제약된 최적화 문제의 예입니다.또한 머신러닝 영역에서 C/C++에서 GA 기반 분류 규칙 프레임워크를 처음부터 구현했습니다.또한 유명한 역전파 알고리즘을 사용하는 대신 인공신경망(ANN) 트레이닝을 위한 샘플 프로젝트에서 GA를 사용했습니다.또한 대학원 연구의 일환으로 EM 기반 Baum-Welch 알고리즘(c/c++에서 다시)에 대한 추가 접근 방식으로 Hidden Markov Models 교육에 GA를 사용했습니다.codechef.com( 멋진 사이트, 월간 프로그래밍 대회)에서 해결할 수 없는 수독을 해결할 대회가 있었습니다(가급적 적은 수의 잘못된 열/행/등으로 접속할 필요가 있습니다). 내가 할 일은 우선 완벽한 스도쿠를 생성하고, 주어진 필드를 재정의하는 것이었습니다. 이 꽤 좋은 기초부터 저는 유전 프로그래밍을 사용하고 솔루션을 개선했습니다. 스도쿠가 300×300에서 검색에 시간이 너무 걸리고, 그 경우는 결정론적 접근이 보이지 않았습니다.codechef.com(훌륭한 사이트, 월간 프로그래밍 대회)에서 해결할 수 없는 수독을 해결해야 하는 대회가 있었습니다(가능한 한 적은 수의 잘못된 열/행/등으로 접속해야 합니다). 제가 해야 할 일은 먼저 완벽한 수독을 생성하고 주어진 필드를 재정의하는 것이었습니다. 이 꽤 좋은 기초에서 저는 유전 프로그래밍을 사용하여 솔루션을 개선했습니다. 수독이 300×300으로 검색에 시간이 너무 많이 걸렸고, 이 경우 결정론적 접근을 생각할 수 없었습니다.축구 칩.AFL(Aussie Rules Football)경기 주별 결과를 예측하는 GA시스템을 구축했습니다.몇년 전 저는 표준 축구장이 따분하게 되었습니다. 누구나 온라인에 접속하면서 언론의 한 전문가들로부터 선택되고 있었습니다. 그래서 방송 저널리즘 전공자에게 이기는 것은 그리 어려운 것은 아니라고 생각했다.그렇죠?저의 최초의 생각은 Massey Ratings에서 결과를 얻은 다음 시즌이 끝날 때, 명성과 영광을 얻은 뒤 나의 전략을 공개하는 것이었습니다. 그러나 Massey가 AFL을 추적하지 않는 것을 발견한 적이 없는 이유에 의한다. 냉소 주의자는 각 AFL게임의 결과가 기본적으로 우연히 된 때문이라고 보고 있지만 최근의 규칙 변경에 대한 불만은 별도의 포럼에 있습니다.시스템은 기본적으로 공격력, 수비, 홈 필드의 이점, 매주 개선(또는 부족)및 그것들 각각에 대한 변경 속도를 감안했어요. 이로써 시즌 중에 각 팀에 일련의 다항 방정식이 생성되었습니다. 주어진 날짜에 대한 각 경기 승자와 점수를 계산할 수 있습니다. 목표는 모든 과거의 게임 결과와 가장 밀접하게 일치하는 계수 세트를 발견하고 이 집합을 사용하여 다음 주의 게임을 예측하는 것이었습니다.실제 시스템은 과거의 게임 결과 90%이상을 정확히 예측한 솔루션을 찾아냅니다. 그 후 주(트레이닝 세트에 없는 주)중에 게임의 약 60~80%를 선택하는 데 성공합니다.결과:팩의 가운데 위에 있습니다. 라스 베이거스에 이기는 큰 상금, 시스템은 없었습니다. 그래도 재미 있었습니다.프레임워크를 사용하지 않고 처음부터 모든 것을 구축했습니다.축구 팁.AFL(Aussie Rules Football) 경기의 주별 결과를 예측하는 GA 시스템을 구축했습니다.몇 년 전, 저는 표준 축구 수영장이 지루해졌어요. 누구나 온라인에 접속하여 미디어의 한 전문가로부터 선택되었습니다. 그래서 방송 저널리즘 전공자를 이기는 것은 그렇게 어렵지 않다고 생각했습니다.그렇죠? 제 첫 번째 생각은 Massey Ratings에서 결과를 얻은 다음 시즌이 끝날 때 명성과 영광을 얻은 후 제 전략을 공개하는 것이었습니다. 그러나 Massey가 AFL을 추적하지 않는 것을 발견한 적이 없는 이유로 인해. 냉소주의자들은 각 AFL 게임의 결과가 기본적으로 우연이 되었기 때문이라고 생각하지만 최근 규칙 변경에 대한 불만은 다른 포럼에 있습니다.시스템은 기본적으로 공격력, 수비력, 홈 필드의 이점, 매주 개선(또는 부족) 및 각각에 대한 변경 속도를 고려했습니다. 이로 인해 시즌 중에 각 팀에 대해 일련의 다항식이 생성되었습니다. 주어진 날짜에 대한 각 경기의 승자와 점수를 계산할 수 있습니다. 목표는 모든 과거 게임의 결과와 가장 밀접하게 일치하는 계수 세트를 찾고 이 세트를 사용하여 다음 주 게임을 예측하는 것이었습니다.실제로 시스템은 과거 게임 결과의 90% 이상을 정확하게 예측한 솔루션을 찾습니다. 그런 다음 다음 주(트레이닝 세트에 없는 주) 중에 게임의 약 60~80%를 선택하는 데 성공합니다.결과: 팩의 한가운데 바로 위에 있습니다. 라스베이거스를 이길 수 있는 큰 상금이나 시스템은 없었습니다. 그래도 재밌었어요.프레임워크를 사용하지 않고 처음부터 모든 것을 구축했습니다.저는 유전 알고리즘(및 일부 관련 기술)을 사용하여 김농가가 잃어버린 신용 카드를 사용하고 MMO비용을 지불하지 않도록 하는 리스크 관리 시스템에 대한 최상의 설정을 결정했다. 시스템은 “기존의 “치(사기인지)을 가진 수천의 트랜잭션을 수신하고, 너무 많은 오검지 없이 사기 트랜잭션을 적절하게 식별하기 위한 최선의 설정의 조합을 찾아냅니다.우리는 거래의 수십(바람)특성에 관한 데이터를 갖고 있으며 각각에 값이 주어지고 합산되어 있었습니다. 합계가 문턱보다 높을 경우 거래는 사기입니다. GA는 다수의 임의의 값 세트를 생성하고 기존의 데이터 코퍼스에 대한 평가하고 가장 높은 점수를 받은 값(사기 탐지 및 헛손질 수 제한의 양쪽에서)를 선택하여 각 세대는 새로운 세대의 후보자를 생산합니다. 특정 가구 수 뒤에 가장 높은 스코어를 획득한 값 세트를 승리자로 여겨졌습니다.테스트하는 기지의 데이터 컬렉션을 작성하는 것은 시스템의 아킬레스 건이었어요. 지불 거부를 기다리고 있으면 사기꾼에 대응할 때 몇달이나 늦어지고 있었습니다. 그러므로 누군가는 별로 기다리지 않고 그 데이터 코퍼스를 구축하기 위해서 대량의 트랜잭션을 수동으로 검토할 필요가 있었습니다.이것으로, 수신된 사기의 대다수를 식별했지만 사기에 가장 취약한 항목에서 1%미만으로 낮출 수는 없었습니다.이들 모든 작업을 perl을 사용하고 실행했습니다. 상당히 오래 된 Linux박스에서 소프트웨어를 한번 실행하면 실행하는데 1-2시간 걸립니다(WAN링크를 통해서 데이터를 로드하는 데 20분 나머지 시간은 쿠란 친구에 걸린다). 주어진 세대의 크기는 사용 가능한 RAM에 의해서 제한되었습니다. 파라미터를 약간 변경하고 반복 실행하고 특히 좋은 결과 세트를 찾아냅니다.전반적으로 수십 종류의 사기 지표의 상대 값을 수동으로 조정할 때 발생하는 일부 오류를 피하고 자신이 준비할 수 있는 보다 좋은 솔루션을 지속적으로 제시했습니다. AFAIK, 아직 사용 중입니다(내가 작성한 지 약 3년).나는 유전 알고리즘(및 일부 관련 기술)을 사용하여 금 농부들이 도난당한 신용카드를 사용하여 MMO 비용을 지불하지 못하도록 하는 위험 관리 시스템에 대한 최상의 설정을 결정했습니다. 시스템은 “알려진” 값(사기인지 아닌지)을 가진 수천 개의 트랜잭션을 수신하여 너무 많은 오탐지 없이 사기 트랜잭션을 적절하게 식별하기 위한 최선의 설정 조합을 찾습니다.우리는 거래의 수십(부울) 특성에 관한 데이터를 가지고 있으며, 각각에 값이 주어지고 합산되어 있었습니다. 합계가 임계값보다 높을 경우 거래는 사기입니다. GA는 다수의 임의의 값 세트를 생성하여 알려진 데이터 코퍼스에 대해 평가하고 가장 높은 점수를 받은 값(사기 탐지 및 오탐지 수 제한 모두에서)을 선택하며, 각 세대는 새로운 세대의 후보자를 생산합니다. 특정 가구 수 이후에 가장 높은 점수를 획득한 값 세트가 승자로 간주되었습니다.테스트할 알려진 데이터 컬렉션을 만드는 것은 시스템의 아킬레스건이었습니다. 지불 거부를 기다렸는데 사기꾼에게 대응할 때 몇 달이나 늦어져 있었습니다. 따라서 누군가는 너무 기다리지 않고 그 데이터 코퍼스를 구축하기 위해 대량의 트랜잭션을 수동으로 검토해야 했습니다.이를 통해 수신된 사기의 대다수를 식별했지만 사기에 가장 취약한 항목에서 1% 미만으로 낮출 수 없었습니다.이 모든 작업을 perl을 사용하여 수행했습니다. 상당히 오래된 Linux 상자에서 소프트웨어를 한 번 실행하면 실행하는 데 1-2시간이 걸립니다(WAN 링크를 통해 데이터를 로드하는 데 20분, 나머지 시간은 크랜칭에 소요됨). 주어진 세대의 크기는 사용 가능한 RAM에 의해 제한되었습니다. 파라미터를 약간 변경하여 반복 실행하고 특히 좋은 결과 세트를 찾습니다.전반적으로 수십 가지 사기 지표의 상대치를 수동으로 조정하고자 할 때 발생하는 일부 오류를 피하고 자신이 직접 만들 수 있는 더 나은 솔루션을 지속적으로 제시했습니다. AFAIK, 아직 사용중입니다(제가 작성한지 약 3년).저의 학부 CompSci학위의 일환으로 우리는 Jikes연구 가상 머신에 최적인 jvm플래그를 찾는 문제를 배정되었습니다. 이는 콘솔에 시간을 갚을 Dicappo벤치 마크 패밀리를 사용하여 평가되었습니다. 결과에 영향을 미치는 하드웨어 지터를 보상하기 위해서 실행하는데 며칠 걸렸었는데, 벤치 마크 제품 군의 런타임을 개선하기 위해서, 이러한 플래그를 바꾸어 분산 지에은티쯔크로그을 작성했습니다. 유일한 문제는 컴파일러 이론(과제 의도)에 대해서 제대로 배우지 않은 것입니다.기존의 기본 플래그로 초기 모집단을 시드 배정국 수 있었지만, 흥미로운 것은 알고리즘이 O3최적화 수준과 매우 유사한 구성을 찾아낸 것입니다( 하지만 실제로는 많은 테스트에서 더 빠른).편집:또, 할당 때문에 Python에서 고유의 유전 알고리즘 프레임워크를 작성하여 다양한 벤치 마크를 실행하기 위해서 popen명령을 사용했습니다. 평가된 배정이 아니면 pyEvolve를 봤을 거예요.나의 학부 CompSci 학위의 일환으로, 우리는 Jikes 연구 가상 머신에 최적의 jvm 플래그를 찾는 문제를 할당받았습니다. 이것은 콘솔에 시간을 돌려주는 Dicappo 벤치마크 패밀리를 사용하여 평가되었습니다. 결과에 영향을 미치는 하드웨어 지터를 보상하기 위해 실행하는 데 며칠이 걸렸지만 벤치마크 제품군의 런타임을 개선하기 위해 이러한 플래그를 전환하는 분산 젠틱 로그를 만들었습니다. 유일한 문제는 컴파일러 이론(과제 의도)에 대해 제대로 배우지 못했다는 것입니다.기존 기본 플래그로 초기 모집단을 시드할 수 있었지만 흥미로운 것은 알고리즘이 O3 최적화 수준과 매우 유사한 구성을 발견했다는 것입니다(하지만 실제로는 많은 테스트에서 더 빠름).편집: 또한 할당을 위해 Python에서 고유한 유전 알고리즘 프레임워크를 만들고 다양한 벤치마크를 실행하기 위해 popen 명령을 사용했습니다. 평가된 할당이 아니었다면 pyEvolve를 봤을 것입니다.나는 이진 문자열로 표현된 파동의 신호 대 잡음비를 최적화하기 위해서 간단한 유전 알고리즘을 사용했습니다. 수백만세대에 걸쳐서 비트를 특정 방법으로 뒤집니 그 웨이브의 신호 대 잡음비를 높이고 변환을 생성할 수 있었습니다. 알고리즘은 “Simulated Annealing” 할지도 모르겠지만, 이 경우는 사용되지 않았습니다. 핵심적으로 유전 알고리즘은 간단하고, 이는 내가 본 사용 사례 정도로 간단해서 세대 생성 및 선택을 위한 프레임워크를 사용하지 않았습니다. 랜덤 시드가 신호 대 잡음만을 사용했습니다. 기능나는 이진 문자열로 표현된 파동의 신호 대 잡음비를 최적화하기 위해 간단한 유전 알고리즘을 사용했습니다. 수백만 세대에 걸쳐 비트를 특정 방법으로 뒤집음으로써 그 웨이브의 신호 대 잡음비를 높이는 변환을 생성할 수 있었습니다. 알고리즘은 “Simulated Annealing”일 수 있지만, 이 경우에는 사용되지 않았습니다. 핵심적으로 유전 알고리즘은 간단했고, 이는 제가 본 사용 사례만큼 간단했기 때문에 세대 생성 및 선택을 위한 프레임워크를 사용하지 않았습니다. 랜덤 시드와 신호 대 잡음만을 사용했습니다. 기능몇년 전 저는 ga를 쓰고 더 좋은 인식률 때문에 asr(자동 음성 인식)문법을 최적화했습니다. 나는 꽤 단순한 선택 목록(GA가 각 슬롯에 대해서 가능한 용어의 조합을 시험하는 장소)부터 시작해서 보다 개방적이고 복잡한 문법까지 작업했습니다. 적합성은 모종의 음성적 거리 함수에 기초하여 용어/순서 간의 분리를 측정하고 결정되었습니다. 나는 또 보다 간결한 표현으로 컴파일된 문법을 찾기 위한 문법에 약한 동등한 변형을 만드는 실험을 했습니다. 최근에는 다양한 알고리즘에서 생성된 솔루션의 품질을 테스트하기 위한 기본 가설로서 이를 사용했습니다. 여기에는 카테고리화 및 여러 종류의 피팅의 문제가 포함됩니다(즉, 데이터 세트에 대해서 검토자가 선택한 세트를 설명하는 “룰”의 작성).몇 년 전 나는 ga를 사용하여 더 나은 인식률을 위해 asr(자동 음성 인식) 문법을 최적화했습니다. 나는 꽤 단순한 선택 목록(GA가 각 슬롯에 대해 가능한 용어 조합을 테스트하는 장소)부터 시작하여 보다 개방적이고 복잡한 문법까지 작업했습니다. 적합성은 모종의 음성적 거리 함수를 기반으로 용어/시퀀스 간의 분리를 측정하여 결정되었습니다. 나는 또한 보다 간결한 표현으로 컴파일된 문법을 찾기 위해 문법에 약하고 동등한 변형을 만드는 실험을 했습니다. 최근에는 다양한 알고리즘에서 생성된 솔루션의 품질을 테스트하기 위한 기본 가설로 이를 사용했습니다. 여기에는 카테고리화 및 다양한 종류의 피팅 문제가 포함됩니다(즉, 데이터 세트에 대해 리뷰자가 선택한 세트를 설명하는 ‘규칙’ 작성).재생되는 음악의 주파수 스펙트럼에서 유용한 패턴을 추출하기 위해서 간단한 GA을 작성했습니다. 출력은 winamp플러그 인으로 그래픽 효과를 구동하는 데 사용되었습니다.입력:몇몇 FFT프레임(2D부동 소수 점 순서 상상)출력:단일 부동 소수 점 값(입력의 가중치 합), 문턱 0.0또는 1.0유전자:입력 가중 피트니스 기능:합리적인 범위 내에서 충격 주기, 펄스 폭 및 BPM의 조합.스펙트럼의 다른 부분과 다른 BPM한계에 맞춰진 몇몇 GA가 있어서 같은 패턴에 수습하는 경향이 없었습니다. 각 모집단의 상위 4개의 출력이 렌더링 엔진에 송신되었습니다.흥미로운 부작용은 전체 인구의 평균 체력이 음악의 변화의 좋은 지표였다는 것이었지만, 일반적으로 조사하는데 4-5초 걸렸습니다.재생되는 음악의 주파수 스펙트럼에서 유용한 패턴을 추출하기 위해 간단한 GA를 만들었습니다. 출력은 winamp 플러그인에서 그래픽 효과를 구동하기 위해 사용되었습니다.입력: 몇 개의 FFT 프레임(2D 부동 소수점 배열 상상) 출력: 단일 부동 소수점 값(입력 가중치 합), 임계값 0.0 또는 1.0 유전자: 입력 가중 피트니스 기능: 합리적인 범위 내에서의 듀티 사이클, 펄스 폭 및 BPM 조합.스펙트럼의 다른 부분과 다른 BPM 한계에 맞춘 여러 GA가 있었기 때문에 동일한 패턴으로 수렴하는 경향이 없었습니다. 각 모집단의 상위 4개 출력이 렌더링 엔진으로 전송되었습니다.흥미로운 부작용은 전체 인구의 평균 체력이 음악 변화의 좋은 지표였다는 것이었지만 일반적으로 조사하는 데 4-5초가 걸렸습니다.학부에서는 NERO(신경망과 유전 알고리즘의 조합)를 사용하여 게임 내 로봇이 지능적인 결정을 내리도록 가르쳤습니다. 그것은 꽤 멋졌다.학부에서는 NERO(신경망과 유전 알고리즘의 조합)를 사용하여 게임 내 로봇이 지능적인 결정을 내리도록 가르쳤습니다. 그것은 꽤 멋졌다.나는 몇주 전에 이 작은 재미 있는 헛간을 만들었습니다. GA을 사용하고 재미 있는 인터넷 화상을 생성합니다. 바보 같지만 웃에는 좋다.http://www.twitterandom.info/GAFunny/이에 대한 몇가지 통찰력. 그것은 몇몇 mysql테이블입니다. 1개는 화상 리스트와 그 스코어(헬스)에 대해서 벌써 1개는 페이지의 하위 이미지로 위치입니다. 하위 화상에는+사이즈, 기울면서 회전,+위치+image_url등 모두 구현되지 않은 몇가지 상세한 내용이 있는 경우가 있습니다. 사람들이 이미지가 얼마나 재미 있을지에 대해서 투표하면서 다음 세대까지 살아남을 가능성이 다소 높아집니다. 생존하면 미미한 돌연변이의 한 5~10의 자손을 낳습니다. 아직 크로스 오버가 없습니다.저는 몇 주 전에 이 작고 재미있는 장식물을 만들었습니다. GA를 사용하여 재미있는 인터넷 이미지를 생성합니다. 바보같지만 웃기엔 좋아.http://www.twitterandom.info/GAFunny/ 이에 대한 몇 가지 통찰력. 그것은 몇 가지 mysql 테이블입니다. 하나는 이미지 목록과 그 점수(피트니스)에 관한 것이고, 다른 하나는 페이지의 하위 이미지와 위치에 관한 것입니다. 하위 이미지에는 + 크기, 기울기, 회전, + 위치, +image_url 등 모두 구현되지 않은 몇 가지 세부 사항이 있을 수 있습니다. 사람들이 이미지가 얼마나 재미있는지 투표함에 따라 다음 세대까지 살아남을 가능성이 다소 높아집니다. 생존하면 약간의 돌연변이가 있는 5~10명의 자손을 낳습니다. 아직 크로스오버가 없습니다.저는 EC(Evolutionary Computation)을 사용하여 기존 프로그램의 오류를 자동적으로 수정하는 방법을 조사하는 팀의 일원입니다. 우리는 실제 소프트웨어 프로젝트에서 많은 실제 오류를 복구하는데 성공했습니다(이 프로젝트의 홈페이지를 참조). 이 EC수리 기술의 2종의 앱이 있습니다.최초의(프로젝트 홈페이지를 통해서 제공되는 코드 및 재생 정보)는 기존 C프로그램에서 구문 분석된 추상 구문 트리를 발전시키고 자체 사용자 정의 EC엔진을 사용하고 Ocaml로 구현됩니다.2번째(프로젝트 홈페이지를 통해서 제공되는 코드 및 재생 정보)는 프로젝트에 대한 개인적인 공헌으로서 여러 프로그래밍 언어로 작성된 프로그램으로 컴파일된 x86어셈블리 또는 Java바이트 코드를 발전시킵니다. 이 애플리케이션은 Clojure에서 구현되어 독자적인 커스텀 EC엔진도 사용합니다.Evolutionary Computation의 좋은 점 중 하나는 기술의 단순성으로 큰 어려움 없이 사용자 정의의 구현을 작성할 수 있다는 것입니다. 무료로 이용할 수 있는 유전 프로그래밍 소개 텍스트에 대해서는 유전 프로그래밍 필드 가이드를 참조하세요.나는 EC(Evolutionary Computation)를 사용하여 기존 프로그램의 버그를 자동으로 수정하는 방법을 조사하는 팀의 일원입니다. 우리는 실제 소프트웨어 프로젝트에서 많은 실제 버그를 복구하는 데 성공했습니다(이 프로젝트 홈페이지 참조). 이 EC 수리 기술의 두 가지 응용 프로그램이 있습니다.첫 번째 (프로젝트 페이지를 통해 제공되는 코드 및 재생 정보)는 기존 C 프로그램에서 구문 분석된 추상 구문 트리를 발전시키고 자체 사용자 정의 EC 엔진을 사용하여 Ocaml에서 구현됩니다.두 번째(프로젝트 페이지를 통해 제공되는 코드 및 재생 정보)는 프로젝트에 대한 개인적인 기여로 여러 프로그래밍 언어로 작성된 프로그램으로 컴파일된 x86 어셈블리 또는 자바 바이트 코드를 발전시킵니다. 이 애플리케이션은 Clojure로 구현되며 자체 커스텀 EC 엔진도 사용합니다.Evolutionary Computation의 좋은 점 중 하나는 기술의 단순성으로 인해 큰 어려움 없이 사용자 정의 구현을 만들 수 있다는 것입니다. 무료로 이용할 수 있는 유전 프로그래밍 소개 텍스트는 유전 프로그래밍 필드 가이드를 참조하십시오.2004년 1월 Amazon Kindle및 기타 메이커가 미국 시장에 출시되기 수년 전에 일본에서만 발매된 최초의 상업용 전자 잉크이다 Sony Librie용 전자 제품을 만들던 Philips New Display Technologies에게 연락을 받았습니다. 유럽. Philips엔지니어에는 큰 문제가 있었습니다. 제품이 시장에 출시되는 몇달 전에 페이지를 변경했을 때 여전히 화면에 잔상이 나타났습니다. 문제는 정전 기장을 생성하는 200의 운전자였습니다. 이들의 드라이버 각각에는 0부터 1000 mV사이 또는 그와 비슷한 값으로 즉시 설정되지 않으면 되지 않는 특정 전압이 있었습니다. 그러나 그것들 중 하나를 바꾸면 모든 게 변합니다.그러므로 각 드라이버의 전압을 개별적으로 최적화하지는 못했어요. 가능한 값 조합의 수는 수십 억개인 특수 카메라가 단일 조합을 평가하는 데 약 1분 걸렸습니다. 엔지니어는 많은 표준 최적화 기술을 시도했습니다만, 아무것도 성공하지 않았습니다.이전, 오픈 소스 커뮤니티에 유전자 프로그래밍 라이브러리를 발표하고 있었으므로, 치프 엔지니어가 저에게 연락했습니다. 그는 GP/GA가 도움이 되는지, 내가 참여할 수 있는지 물었습니다. 나는 그렇게 해서 약 1개월 동안 우리는 합성 데이터에 대해서 GA라이브러리를 작성하고 조정하는 그를 시스템에 통합했습니다. 그 뒤 어느 주말에 실제와 함께 라이브에서 실행되도록 했습니다.다음 월요일, 나는 그와 그들의 하드웨어 디자이너에서 GA가 발견한 놀라운 결과를 아무도 믿을 수 없다는 놀라운 전자 메일을 받았습니다. 이것이 바로 그것이었다. 그 해의 끝에 제품이 시장에 출시되었습니다.나는 그것에 대해서 1센트도 받지 않았지만,”자랑” 할 권리가 있습니다. 그들은 처음부터 이미 예산을 넘는다고 해서 작업을 시작하기 전에 거래가 무엇인지를 알고 있었습니다. 그리고 GA적용에 대해서 멋진 이야기입니다. :)2004년 1월 아마존 킨들 및 기타 제조사들이 미국 시장에 출시되기 몇 년 전 일본에서만 출시된 최초의 상업용 전자 잉크인 소니 리브리용 전자 제품을 제조하던 필립스 New Display Technologies로부터 연락을 받았습니다. 유럽.필립스 엔지니어에게는 큰 문제가 있었습니다. 제품이 시장에 출시되기 몇 달 전 페이지를 변경했을 때 여전히 화면에 잔상이 나타났습니다. 문제는 정전기장을 생성하는 200개의 드라이버였습니다. 이들 드라이버 각각에는 0에서 1000mV 사이 또는 그와 비슷한 값으로 즉시 설정되어야 하는 특정 전압이 있었습니다. 하지만 그것들 중 하나를 바꾸면 모든 것이 바뀝니다.따라서 각 드라이버의 전압을 개별적으로 최적화할 수 없었습니다. 가능한 값 조합의 수는 수십억 개이며 특수 카메라가 단일 조합을 평가하는 데 약 1분이 걸렸습니다. 엔지니어는 많은 표준 최적화 기술을 시도했지만 아무것도 성공하지 못했습니다.이전에 오픈 소스 커뮤니티에 유전자 프로그래밍 라이브러리를 출시했기 때문에 수석 엔지니어가 저에게 연락했습니다. 그는 GP/GA가 도움이 되는지, 내가 참여할 수 있는지 물었습니다. 나는 그렇게 약 한 달 동안 우리는 합성 데이터에 대해 GA 라이브러리를 만들고 조정했으며 그를 시스템에 통합했습니다. 그 후 어느 주말에 실제와 함께 라이브로 실행되도록 했습니다.다음 월요일, 저는 그와 그들의 하드웨어 디자이너로부터 GA가 발견한 놀라운 결과를 아무도 믿지 못한다는 놀라운 이메일을 받았습니다. 이게 바로 그거였어. 그해 말에 제품이 시장에 출시되었습니다.저는 그것에 대해 1센트도 받지 못했지만 ‘자랑’할 권리가 있습니다. 그들은 처음부터 이미 예산을 초과했다고 말했기 때문에 작업을 시작하기 전에 거래가 무엇인지 알고 있었습니다. 그리고 GA 적용에 대한 훌륭한 이야기입니다. :)2007-9년에 저는 데이터 매트릭스 패턴을 읽기 위한 소프트웨어를 개발했습니다. 많은 경우 이들의 패턴은 모든 종류의 반사율 특성, 화학적으로 부식된 퍼지 표시 등으로 긁힌 표면에 넣어 읽기가 힘들었습니다. GA을 사용하고 비전 알고리즘의 다양한 파라미터를 미조정하고 기존의 속성을 가진 300의 이미지 데이터베이스에서 최고의 결과를 제공했습니다. 파라미터는 다운 샘플링 해상도, RANSAC파라미터, 침식 및 팽창의 양, 저주파 통과 통과 필터링 반경 및 기타 몇가지의 것이었습니다. 며칠에 걸쳐서 최적화를 실행하면, 최적화 단계에서 볼 수 없는 화상 테스트 세트의 순진한 값보다 약 20% 좋은 결과가 생성되었습니다.이 시스템은 완전히 처음부터 작성됐고 다른 라이브러리를 사용하지 않습니다. 저는 신뢰할 만한 결과를 제공한다면 그런 것을 사용하는 것은 반대하지 않지만, 라이센스 호환성 및 코드 이식성의 문제에 주의해야 합니다.2007-9년에 저는 데이터 매트릭스 패턴을 읽기 위한 소프트웨어를 개발했습니다. 대부분의 경우 이 패턴들은 모든 종류의 반사율 특성, 화학적으로 에칭된 퍼지 표시 등으로 긁힌 표면에 집어넣기 때문에 읽기가 어려웠습니다. GA를 사용하여 비전 알고리즘의 다양한 파라미터를 미세 조정하고 알려진 속성을 가진 300개의 이미지 데이터베이스에서 최고의 결과를 제공했습니다. 파라미터는 다운샘플링 해상도, LANSAC 파라미터, 침식 및 팽창의 양, 저역 통과 필터링 반경 및 기타 몇 가지였습니다. 며칠에 걸쳐 최적화를 실행하면 최적화 단계에서는 볼 수 없는 이미지 테스트 세트의 순진한 값보다 약 20% 우수한 결과가 생성되었습니다.이 시스템은 완전히 처음부터 작성되었으며 다른 라이브러리를 사용하지 않습니다. 나는 신뢰할 수 있는 결과를 제공한다면 그러한 것을 사용하는 것에 반대하지 않지만 라이센스 호환성 및 코드 이식성 문제에 주의해야 합니다.한번 GA을 사용하고 메모리 주소에 대한 해시 함수를 최적화했습니다. 주소는 4K또는 8K페이지 크기였으므로, 주소의 비트 패턴인 정도 예측 가능성을 나타냈습니다(최하위 비트는 모두 제로로 중간의 비트는 정기적으로 증가하는 등). 원래 해시 함수는 “덩어리”이었습니다. 3번째의 해시 버켓마다. 개선된 알고리즘은 거의 완벽한 분포를 나타냈습니다.일단 GA를 사용하여 메모리 주소에 대한 해시 함수를 최적화했습니다. 주소는 4K 또는 8K 페이지 크기였기 때문에 주소의 비트 패턴으로 어느 정도 예측 가능성을 보였습니다(꼴찌의 비트는 모두 제로이고 중간의 비트는 정기적으로 증가하는 등). 원래 해시함수는 ‘덩어리’였습니다. 세 번째 해시 버킷마다. 개선된 알고리즘은 거의 완벽한 분포를 보였습니다.저는 어릴 때 GA을 실험했다. 다음과 같이 동작하는 시뮬레이터를 Python에서 작성했습니다.유전자는 신경 회로망의 무게를 인코딩했습니다.뉴럴 네트워크의 입력은 터치를 검출하는 “안테나”이었습니다. 값이 높을수록 아주 가까운, 0은 접촉하지 않는 것을 의미합니다.출력은 2가지”바퀴”이었습니다. 이륜 모두 앞으로 가면 그 사람이 앞으로 나아갑니다. 바퀴가 반대 방향이라면, 그 사람은 돌아봤습니다. 출력의 강도가 바퀴의 회전 속도를 결정했다.간단한 미로가 작성되었습니다. 그것은 정말 간단했다. 심지어 우둔이었습니다. 화면 하단에는 출발 지점이 있는 상단에는 골이 있고, 그 사이에 4개의 벽이 있었습니다. 각 벽에는 랜덤으로 공간을 잡아 항상 패스가 있었습니다.나는 처음 여러 사람들(나는 그들을 버그라고 생각했다)을 시작했다. 한 사람이 목표에 도달하거나 제한 시간에 도달하자 체력이 계산되었습니다. 당시 골까지의 거리에 반비례했다.그 뒤 그들을 페어로 “육종” 하고 다음 세대를 만들었습니다. 번식에 뽑힐 확률은 그 적합성에 비례했다. 가끔 이는 상대 적합도가 매우 높다고 자신과 반복 교배되는 것을 의미했습니다.나는 그들이 “왼쪽 벽 포섭”행동을 발전시킨다고 생각했지만 그들은 항상 최적이지 않은 것에 따르게 보였습니다. 모든 실험에서 버그는 스파이럴 패턴에 수습했습니다. 그들은 오른쪽 벽에 도착하기까지 밖에 나선 모양으로 나왔습니다. 그들은 그에 따른 간격에 이르렀을 때 나선 밑에(격차에서 멀어진다)주변을 돌아다녔습니다. 그들은 왼쪽에 270도 회전하며 일반적으로 틈새에 낍니다. 이로써 대부분의 벽을 통과하고 종종 목표에 도달할 수 있습니다.내가 추가한 기능의 1개는 개인 간의 관련성을 추적하기 위해서 유전자에 색 벡터를 들어간 것입니다. 몇세대 후에는 모두 같은 색이 되고 더 좋은 번식 전략이 필요한 것으로 압니다.나는 그들이 더 좋은 전략을 개발하도록 노력했습니다. 메모리와 모든 것을 추가하고, 뉴럴 네트워크를 복잡하게 했습니다. 도움이 되지 않았습니다. 저는 항상 같은 전략을 보아 왔다.100세대 후에야 조작되는 다른 유전자 풀을 갖는 등 다양한 시도를 했습니다. 그러나 어느 것도 그들을 더 좋은 전략에 강요하는 것은 없습니다. 아마 불가능했지.벌써 1개의 흥미로운 점은 시간의 경과에 따른 피트니스 그래프입니다. 가장 대부분력이 오르기 전에 함께 떨어지는 확실한 패턴이 있었습니다. 나는 진화의 책에서 그 가능성에 대해서 이야기하는 것을 본 적이 없습니다.나는 어렸을 때 GA를 실험했어. 다음과 같이 작동하는 시뮬레이터를 Python으로 만들었습니다.유전자는 신경망의 무게를 인코딩했습니다.신경망의 입력은 터치를 검출하는 ‘안테나’였습니다. 값이 높을수록 매우 가깝고 0은 접촉하지 않음을 의미합니다.출력은 2개의 ‘바퀴’였습니다. 두 바퀴 다 앞으로 나아가면 그 사람이 앞으로 나아갑니다. 바퀴가 반대 방향이면 그 사람은 돌아섰어요. 출력 강도가 바퀴의 회전 속도를 결정했습니다.간단한 미로가 작성되었습니다. 그건 정말 쉬웠어요. 심지어 어리석었어요. 화면 하단에는 시작점이 있고 상단에는 골이 있고 그 사이에 4개의 벽이 있었습니다. 각 벽에는 무작위로 공간이 제거되고 항상 경로가 있었습니다.나는 처음에 랜덤한 사람들(나는 그들을 버그라고 생각했다)을 시작했다. 한 사람이 목표에 도달하거나 제한 시간에 도달하자마자 체력이 계산되었습니다. 당시 골까지의 거리에 반비례했다.그 후 그들을 짝지어 ‘육종’하여 다음 세대를 만들었습니다. 번식에 선택될 확률은 그 적합성에 비례했다. 때때로 이것은 상대 적합도가 매우 높으면 자신과 반복 교배되는 것을 의미했습니다.저는 그들이 ‘좌벽 껴안기’ 행동을 발전시킬 것이라고 생각했지만, 그들은 항상 최적은 아닌 것을 따르는 것처럼 보였습니다. 모든 실험에서 버그는 나선형 패턴으로 수렴했습니다. 그들은 오른쪽 벽에 닿을 때까지 바깥으로 나선형으로 나왔습니다. 그들은 그것에 따라 간격에 도달했을 때 나선형으로 아래로 (격차에서 멀어지면서) 주위를 돌았습니다. 그들은 왼쪽으로 270도 회전하여 일반적으로 틈새로 들어갑니다. 이를 통해 대부분의 벽을 통과하고 종종 목표에 도달할 수 있습니다.내가 추가한 기능 중 하나는 개인 간의 연관성을 추적하기 위해 유전자에 색 벡터를 넣는 것입니다. 몇 세대 후에는 모두 같은 색이 되어 더 나은 번식 전략이 필요하다는 것을 알 수 있습니다.저는 그들이 더 나은 전략을 개발하도록 노력했습니다. 메모리와 모든 것을 추가하여 신경망을 복잡하게 만들었습니다. 도움이 되지 않았어요. 나는 항상 같은 전략을 봐왔어.100세대 후에야 재조합할 수 있는 다른 유전자 풀을 갖는 등 다양한 시도를 했습니다. 그러나 어느 것도 그들을 더 나은 전략으로 밀어붙이지는 않습니다. 아마 불가능했을 거예요.또 하나의 흥미로운 점은 시간의 경과에 따른 피트니스 그래프입니다. 최대한 힘이 오르기 전에 내려갈 것 같은 확실한 패턴이 있었어요. 저는 진화 책에서 그 가능성에 대해 이야기하는 것을 본 적이 없습니다.진화 계산 대학원 수업:TopCoder Marathon Match 49:MegaParty용 솔루션을 개발했습니다. 저의 소규모 그룹은 다양한 도메인 표현을 테스트하며 다른 표현이 정답을 찾아 GA의 능력에 어떤 영향을 주는지 테스트하고 있었습니다. 우리는 이 문제의 독자적인 코드를 실행했습니다.신경화 및 생성 및 발달 시스템, 대학원 수업:컴퓨터 플레이어의 최소 최대 트리에 사용되는 Othello게임 보드 평가기를 개발했습니다. 플레이어는 게임에 대한 심층적인 평가를 실시하도록 설정되어 코너 킥을 매우 중요시하는 욕심 많은 컴퓨터 플레이어와 플레이하도록 훈련되었습니다. 훈련 선수는 3개 또는 4개 중 1개를 보았습니다.(응답하려면 구성 파일을 살펴볼 필요가 있고 다른 컴퓨터에 있습니다). 실험의 목표는 새로운 검색을 게임 보드 평가 영역에서 기존의 피트니스 기반의 검색과 비교하는 것이었습니다. 결과는 안타깝게도 상대적으로 결정적이지 않았습니다. 창의 검색과 적합성 기반의 검색 방법 모두가 솔루션에 도달했습니다만(Othello도메인에서 참신한 검색을 사용할 수 있음을 나타내고 있다)이 도메인에 숨겨진 노드 없이 솔루션을 가질 수 있었습니다. 분명히 나는 선형 솔루션을 사용할 수 있다면 충분히 유능한 트레이너를 만들고 있지 않는다. 저는 헬스 기반의 검색 구현이 이번에는 참신한 검색 구현보다 빠른 솔루션을 생성했다고 생각합니다(항상 그렇지 않습니다). 어느 쪽이든, 신경 회로망 코드에 대해서”Another NEAT Java Implementation”인 ANJI을 다양한 수정과 함께 사용했습니다. 내가 직접 쓴 오뎃로게ー무.진화계산대학원 수업: TopCoder Marathon Match 49:Mega Party용 솔루션을 개발하였습니다. 제 소규모 그룹은 다양한 도메인 표현을 테스트하고 다른 표현이 정답을 찾는 GA의 능력에 어떤 영향을 미치는지 테스트하고 있었습니다. 우리는 이 문제의 독자적인 코드를 실행했습니다.신경 진화 및 생성 및 발달 시스템, 대학원 수업: 컴퓨터 플레이어 최소-최대 트리에 사용되는 Othello 게임 보드 평가기를 개발하였습니다. 플레이어는 게임에 대한 심층적인 평가를 수행하도록 설정되어 코너킥을 매우 중요시하는 욕심 많은 컴퓨터 플레이어와 플레이하도록 훈련되었습니다. 훈련 선수는 3개 또는 4개 중 하나를 보았습니다(응답하려면 구성 파일을 조사해야 하며 다른 컴퓨터에 있습니다). 실험의 목표는 참신한 검색을 게임 보드 평가 영역에서 기존 피트니스 기반 검색과 비교하는 것이었습니다. 결과는 유감스럽게도 상대적으로 결정적이지 않았습니다. 참신 검색과 적합성 기반 검색 방법 모두 솔루션에 도달했지만(Othello 도메인에서 참신 검색을 사용할 수 있음을 보여줌) 이 도메인에 숨겨진 노드 없이 솔루션을 가질 수 있었습니다. 분명히, 저는 선형 솔루션을 사용할 수 있는 경우 충분히 유능한 트레이너를 만들지 않았습니다. 저는 피트니스 기반 검색 구현이 이번에는 참신한 검색 구현보다 빠르게 솔루션을 생성했다고 생각합니다(항상 그렇지는 않습니다). 어느 쪽이든, 뉴럴 네트워크 코드에 대해서 「Another NEAT Java Implementation」인 ANJI를 다양한 수정과 함께 사용했습니다. 내가 직접 쓴 오델로 게임.얼마 전이지만, HST(허블 우주 망원경)이미지에서 우주선의 흔적을 없애는 데, 실제로 이미지 처리 커널을 발전시키기 위한 GA을 실행했습니다. 표준적인 어프로치는, Hubble에서 다중 노출을 잡고 모든 이미지로 같은 항목만 유지하는 것입니다. HST의 시간은 매우 중요하므로 저는 천문학 애호가 최근 진화 계산에 관한 회의에 참석한 적이 있고 GA을 사용하고 단일 노출을 정리하는 방법에 대해서 생각했습니다.개인은 3×3픽셀 영역을 입력으로 사용하고 몇가지 계산을 하고 중앙 픽셀을 수정 여부와 수정 방법에 대해서 결정을 내린 나무의 형태였습니다. 적합성은 출력을 기존 방식(예:누적 노출)로 정리한 영상과 비교하고 판단했습니다.그것은 실제로는 일종의 효과가 있었지만, 원래의 접근을 보증하는 데 충분하지 못했어요. 제 논문에 시간의 제약이 없으면 알고리즘에서 사용할 수 있는 유전자 부분의 저장고를 확장했는지도 모릅니다. 상당히 개선했다고 확신합니다.사용된 라이브러리:제 기억이 맞다면, 천문 이미지 데이터 처리 및 I/O을 위한 IRAF및 cfitsio.얼마 전에 HST(허블우주망원경) 이미지에서 우주선의 흔적을 제거하기 위해 실제로 이미지 처리 커널을 발전시키기 위해 GA를 실행했습니다. 표준 접근 방식은 Hubble에서 다중 노출을 취하고 모든 이미지에서 동일한 항목만 유지하는 것입니다. HST 시간은 매우 중요하기 때문에 나는 천문학 애호가이고 최근 진화 계산에 관한 회의에 참석한 적이 있어 GA를 사용하여 단일 노출을 정리하는 방법에 대해 생각했습니다.개인은 3×3 픽셀 영역을 입력으로 사용하여 몇 가지 계산을 하고 중앙 픽셀 수정 여부와 수정 방법에 대해 결정을 내리는 나무 모양이었습니다. 적합성은 출력을 기존 방식(예: 누적 노출)으로 정리한 화상과 비교해 판단했습니다.그것은 실제로는 일종의 효과가 있었지만 원래의 접근법을 보장하기에 충분하지 않았습니다. 제 논문에 시간 제약이 없었다면 알고리즘에서 사용할 수 있는 유전자 부분의 저장소를 확장했을지도 모릅니다. 상당히 개선되었다고 확신합니다.사용된 라이브러리: 내 기억이 맞다면 천문 이미지 데이터 처리 및 I/O를 위한 IRAF 및 cfitsio.저는 1992년에 당사가 화물 산업을 위해서 개발한 3D레이저 표면 프로필 시스템 때문에 사제 GA을 개발했습니다.이 시스템은 3차원 삼각 측량에 의존하는 커스터마이즈 레이저 라인 스캐너이다 512×512회로(커스터마이즈 된 캡쳐 hw를 포함)을 사용했습니다. 카메라와 레이저 사이의 거리는 결코 정확하지 않은 카메라의 초점은 예견됐던 256,256의 위치에 발견되지 않았습니다!표준 기하학과 시뮬레이션된 아닐 스타일 방정식의 해답을 사용하고 보정 파라미터를 시행하고 해결하는 것은 악몽이었습니다.유전 알고리즘은 저녁에 만들어지고 나는 그것을 테스트하기 위해서 보정 큐브를 만들었습니다. 나는 큐브 치수를 높은 정도로 알고 있었으므로, 나의 GA가 생산 변동을 극복할 수 있는 각 스캔 장치에 대한 사용자 정의 삼각 측량 파라미터 세트를 발전시킬 수 있다는 아이디어였습니다.트릭이 있었습니다. 저는 아무리 빨리 얘기해도 놀랐어! 약 10세대 안에 나의 “가상”큐브(원래 스캔으로 생성되며, 보정 파라미터로 재생 가능)은 실제로 큐브처럼 보였습니다! 약 50가구 후에 필요한 보정을 받았습니다.나는 1992년에 당사가 화물 산업을 위해 개발한 3D 레이저 표면 프로파일 시스템을 위해 수제 GA를 개발했습니다.이 시스템은 3차원 삼각측량에 의존하여 커스터마이징 레이저 라인 스캐너인 512×512 카메라(커스터마이징된 캡처 hw 포함)를 사용했습니다. 카메라와 레이저 사이의 거리는 결코 정확하지 않았고 카메라 초점은 예상했던 256, 256 위치에서 찾을 수 없었습니다! 표준 기하학과 시뮬레이션된 어닐 스타일 방정식의 해를 사용하여 교정 파라미터를 시도하고 해결하는 것은 악몽이었습니다.유전 알고리즘은 저녁에 만들어졌고, 저는 그것을 테스트하기 위해 보정 큐브를 만들었습니다. 나는 큐브 치수를 높은 정확도로 알고 있었기 때문에 나의 GA가 생산 변동을 극복할 수 있는 각 스캐닝 유닛에 대한 사용자 정의 삼각측량 파라미터 세트를 발전시킬 수 있다는 아이디어였습니다.트릭이 효과가 있었어요. 나는 아무리 빨리 말해도 놀랐어! 약 10세대 이내에, 나의 「가상」큐브(원래 스캔으로 생성되어 보정 파라미터로 재생 가능)는 실제로 큐브처럼 보였습니다! 약 50가구 후에 필요한 보정을 받았습니다.많은 문제를 해결하기 위해서”GALAB”이라는 완전한 GA프레임워크를 만들었습니다.중복이나 공백의 위치를 줄이기 위해서 GSMANT(BTS)를 찾습니다.자원 제약 프로젝트 스케줄. 진화하는 그림 만들기.(에보 피크)여행 하는 외판원 문제. N- 퀸 및 N-컬러의 문제.나이트 투어&배낭 문제.매직 스퀘어와 스도쿠 퍼즐.Superstring문제에 기초한 문자열 압축. 2D포장 문제.작은 인공 생명 APP. 루빅 퍼즐.많은 문제를 해결하기 위해 ‘GALAB’라는 완전한 GA 프레임워크를 만들었습니다.겹침이나 공백 위치를 줄이기 위해 GSMANT(BTS)를 찾습니다.리소스 제약 프로젝트 일정. 진화하는 그림 만들기.(에보픽) 여행하는 세일즈맨 문제. N-퀸 및 N-컬러 문제.나이트 투어 & 배낭 문제.매직 스퀘어와 수독 퍼즐.Superstring 문제에 기반한 문자열 압축. 2D 패키징 문제.작은 인공 생명 앱 루빅 퍼즐학교 세미나에서는 음악 모드에 근거하고 음악을 생성하는 애플리케이션을 개발합니다. 프로그램은 Java에서 축적되고 출력은 노래를 포함한 미디어 파일이었습니다. 우리는 음악을 생성하기 위해서 GA의 독특한 접근을 사용합니다. 이 프로그램은 새로 작곡을 탐색하는데 도움이 될 것입니다.학교 세미나에서는 음악 모드를 기반으로 음악을 생성하는 애플리케이션을 개발합니다. 프로그램은 자바에서 빌드되었고 출력은 노래를 포함한 미디어 파일이었습니다. 우리는 음악을 생성하기 위해 GA의 독특한 접근법을 사용합니다. 이 프로그램은 새로운 작곡을 탐색하는 데 도움이 될 것이라고 생각합니다.나는 결혼식 피로연에서 좌석 배분을 최적화하기 위해서 GA을 사용했다. 테이블 10개에서 80명. 평가 기능은 사람들과 데이트하고, 공통점이 있는 사람들을 모아 극단적인 견해를 가진 사람들을 다른 테이블에 앉는 것에 기초하고 있었습니다.몇번이나 실행했습니다. 매번 나는 9개의 좋은 테이블과 모든 기묘한 공 있는 테이블을 손에 넣었습니다. 결국 아내는 좌석 배치를 했다.나 여행 세일즈 맨 옵티마이저는 염색체를 여정에 매핑 할 새로운 방법을 사용하여 잘못된 여행을 생성할 위험 없이 염색체를 번식시키고 돌연변이 시키는 것을 쉽게 했습니다.갱신:몇명이 방법을 물었다… 임의이지만 일관된 순서(예:알파벳 순)로 게스트(또는 도시)배열에서 시작됩니다. 이를 참조 솔루션이라고 합니다. 고객의 색인을 좌석 번호와 생각하세요.이 과정을 염색체에서 직접 인코딩하는 대신 참조 솔루션을 새 솔루션에 변환하기 위한 가이던스를 인코딩합니다. 특히 염색체를 교환하는 배열의 인덱스의 목록으로 다룹니다. 염색체를 해독하기 위한 참조 솔루션으로서 시작하고 염색체에 표시되어 있는 모든 스와프를 적용합니다. 배열에서 2개의 아이템을 바꾸면, 항상 유효한 솔루션입니다. 모든 게스트(또는 도시)는 여전히 정확히 1회 나타납니다.그러므로, 염색체는 랜덤 하게 생성, 돌연변이 및 다른 사람과 교배할 수 있고 항상 유효한 솔루션을 생성합니다.나는 결혼식 피로연에서 좌석 배정을 최적화하기 위해 GA를 사용했습니다. 테이블 10개에 80명. 평가 기능은 사람들과 데이트하고 공통점이 있는 사람들을 모으고 극단적인 견해를 가진 사람들을 다른 테이블에 앉히는 것에 기반을 두고 있었습니다.여러 번 실행했어요. 매번 저는 9개의 좋은 테이블과 모든 기묘한 공이 있는 테이블을 손에 넣었습니다. 결국 아내는 자리 배정을 했다.내가 여행하는 세일즈맨 옵티마이저는 염색체를 여정에 매핑하는 새로운 방법을 사용하여 잘못된 여행을 생성할 위험 없이 염색체를 번식시키고 돌연변이시키는 것을 쉽게 했습니다.업데이트: 몇 명이 방법을 물었기 때문에…임의이지만 일관된 순서(예: 알파벳 순)로 게스트(또는 도시) 배열에서 시작합니다. 이것을 참조 솔루션이라고 합니다. 고객님의 색인을 좌석번호로 생각하시면 됩니다.이 절차를 염색체에서 직접 인코딩하는 대신 참조 솔루션을 새로운 솔루션으로 변환하기 위한 지침을 인코딩합니다. 특히 염색체를 교환하는 배열의 인덱스 목록으로 다룹니다. 염색체 해독을 위한 참조 솔루션으로 시작하여 염색체에 표시된 모든 스왑을 적용합니다. 배열에서 2개의 아이템을 전환하면 항상 유효한 솔루션이 됩니다. 모든 게스트(또는 도시)는 여전히 정확하게 1회 나타납니다.따라서 염색체는 무작위로 생성, 돌연변이 및 다른 사람과 교배할 수 있으며 항상 유효한 솔루션을 생성합니다.동료와 저는 회사가 요구하는 다양한 기준을 사용하고 트럭에 화물을 싣고 솔루션을 개발 중입니다. 나는 그가 공격적인 탈분지와 함께 Branch And Bound를 사용하는 동안 Genetic Algorithm솔루션을 연구하고 있습니다. 우리는 아직 이 솔루션을 구현하고있습니다만, 지금까지 좋은 결과를 얻고 있습니다.동료와 저는 회사가 요구하는 다양한 기준을 사용하여 트럭에 화물을 싣는 솔루션을 개발 중입니다. 나는 그가 공격적인 가지치기와 함께 브랜치 앤드 파운드를 사용하는 동안 제네틱 알고리즘을 연구하고 있습니다. 우리는 아직 이 솔루션을 구현하고 있지만, 지금까지 좋은 결과를 얻고 있습니다.직장에서 다음과 같은 문제가 있었습니다. M개의 작업과 N개의 DSP가 주어졌을 때 DSP에 작업을 할당하는 최선의 방법은 무엇입니까? “최고”은 “가장 로드된 DSP의 부하를 최소화”로 정의되었습니다. 다른 타입의 작업이 다양한 작업 유형은 할당된 위치에 의해서 다양한 성능 파급 효과를 갖고 있어 작업-DSP할당 세트를 “DNA문자열”와 인코딩한 뒤 유전자 알고리즘을 사용하여”번식” 했습니다. 제가 할 수 있는 최고의 할당 문자열.그것은 잘 기능했습니다(모든 가능한 조합을 평가하기 이전의 방법보다 훨씬 뛰어납니다. 사소한 문제 크기로 완료하는데 몇년이나 걸렸을까요!)유일한 문제는 말하는 법이 없다는 것입니다. 최적인 솔루션에 도달했는지. 현재의 “최선의 노력”이 충분히 좋을지 여부만 결정할 수 있는지 보다 잘 되는지를 확인하기 위해서 보다 오래 실행할 수 있습니다.직장에서 다음과 같은 문제가 있었습니다. M개의 작업과 N개의 DSP가 주어졌을 때 DSP에 작업을 할당하는 가장 좋은 방법은 무엇입니까? “최고”는 “가장 로드된 DSP의 부하를 최소화”라고 정의되었습니다. 다른 유형의 작업이 있었고 다양한 작업 유형은 할당된 위치에 따라 다양한 성능 파급 효과를 가지고 있었기 때문에 작업 대 DSP 할당 세트를 “DNA 문자열”로 인코딩한 후 유전자 알고리즘을 사용하여 “번식”했습니다. 내가 할 수 있는 최고의 할당 문자열.그것은 꽤 잘 작동했다(모든 가능한 조합을 평가하기 이전의 방법보다 훨씬 낫다… 사소한 문제 크기로 완료하는 데 수년이 걸렸을 것이다).!) 유일한 문제는 말할 방법이 없다는 것입니다. 최적의 솔루션에 도달했는지 여부. 현재의 ‘최선의 노력’이 충분히 좋은지 여부만 결정할 수 있는지, 더 잘할 수 있는지 확인하기 위해 더 오래 실행할 수 있습니다.직장에서 다음과 같은 문제가 있었습니다. M개의 작업과 N개의 DSP가 주어졌을 때 DSP에 작업을 할당하는 가장 좋은 방법은 무엇입니까? “최고”는 “가장 로드된 DSP의 부하를 최소화”라고 정의되었습니다. 다른 유형의 작업이 있었고 다양한 작업 유형은 할당된 위치에 따라 다양한 성능 파급 효과를 가지고 있었기 때문에 작업 대 DSP 할당 세트를 “DNA 문자열”로 인코딩한 후 유전자 알고리즘을 사용하여 “번식”했습니다. 내가 할 수 있는 최고의 할당 문자열.그것은 꽤 잘 작동했다(모든 가능한 조합을 평가하기 이전의 방법보다 훨씬 낫다… 사소한 문제 크기로 완료하는 데 수년이 걸렸을 것이다).!) 유일한 문제는 말할 방법이 없다는 것입니다. 최적의 솔루션에 도달했는지 여부. 현재의 ‘최선의 노력’이 충분히 좋은지 여부만 결정할 수 있는지, 더 잘할 수 있는지 확인하기 위해 더 오래 실행할 수 있습니다.나는 이 작은 세계에 사는 작은 동물을 만들었습니다. 그들은 세계에서 일부의 입력을 받은 신경 회로망 두뇌를 가졌으며, 그 출력은 다른 행동 사이에 움직임을 위한 벡터이었습니다. 그들의 두뇌는 “유전자”였습니다.프로그램은 여러 뇌를 가진 여러 동물의 그룹에서 시작됐습니다. 입력 및 출력 뉴런은 정적이지만, 그 사이에 있는 것은 정적이 아닙니다.환경에는 식량과 위험이 있습니다. 음식은 에너지를 증가시키고 에너지가 충분하면 교미할 수 있습니다. 리스크는 에너지를 감소시키고 에너지가 제로의 경우에 사망했다.결국 생물은 세계를 돌아다니며 먹이를 발견하고 위험을 피하도록 진화했습니다.조금 실험을 하기로 했습니다. 저는 생물의 뇌에 “입”이라는 출력 뉴런과 “귀”라는 입력 뉴런을 줬다. 재기동하고 공간을 최대화하기 위해서 진화하고 각각의 생물이 각 부분에 머물게 놀랐습니다(음식은 무작위로 배치된다). 그들은 서로 협력하고 서로 방해하지 않는 것을 배웠습니다. 항상 예외는 있었습니다.그리고 흥미로운 것을 시도했다. 나는 죽은 생물이 음식이 될 것입니다. 무슨 일이 있었는지 추측하고 보세요! 떼처럼 공격하는 생물과 회피율이 높은 생물의 2종류가 진화했습니다.여기서 교훈은 무엇입니까? 커뮤니케이션은 협력을 의미합니다. 남을 해할 무언가를 얻는 요소를 도입하면 바로 협력이 파괴됩니다.이것이 자유 시장과 자본주의 체제에 어떻게 반영되는지 궁금합니다. 즉 기업이 경쟁에 피해를 주고 경쟁에서 벗어난다면 경쟁에 피해를 입히기 때문에 최선을 다하는 것은 분명합니다.편집한다:프레임워크를 사용하지 않고 C++로 작성했습니다. 자신의 뉴럴 네트워크와 GA코드를 작성했습니다. 에릭, 그럴듯한다고 하셔서 감사합니다. 사람들은 일반적으로 GA의 힘을 믿지 않습니다(제한은 분명하지만). GA는 단순하지만 간단하지 않아요.혐의자 때문에, 뉴럴 네트워크는 2개 이상의 층이 있는 경우 모든 기능을 시뮬레이트 할 수 있음이 입증되었습니다. GA는 로컬 및 잠재적으로 글로벌 최소치를 찾아 솔루션 공간을 탐색하는 매우 간단한 방법입니다. GA와 신경 회로망을 조합하면 일반적인 문제에 대한 대략적인 솔루션을 찾는 함수를 찾는 좋은 방법이 있습니다. 우리는 신경 회로망을 사용하기 때문에 다른 사람이 GA을 사용하는 것처럼 함수에 대한 일부 입력이 아니라 일부의 입력에 대해서 함수를 최적화하고 있습니다.다음은 생존 그 시위 코드입니다. http://www.mempko.com/darcs/neural/demos/eaters/빌드 지침:darcs, libboost, liballegro, gcc, cmake, make설치 darcs clone-lazy http://www.mempko.com/darcs/neural/cd neuralcmake . makecd demos/eaters./eaters집을 페인트 칠할 때 정확한 색의 배합을 얻는 것은 종종 어렵습니다. 대부분의 경우, 염두에 두는 색이 있지만 그 색 중 하나 없는 경우는 벤더가 표시합니다.어제 GA연구원의 내 교수가 독일에서 있었던 실화를 언급했습니다( 죄송합니다.더 이상 참고할 자료가 없습니다. 네, 요청의 분이 계시다면 찾을 수 있습니다). 이 사람(칼라의 사람과 합시다)는 사람들이 고객이 염두에 둔 것과 가장 유사한 정확한 컬러 코드(RGB)을 찾는 걸 돕기 위하여 찾아왔다. 그의 방식은 다음과 같습니다.컬러 사나희는 GA을 사용하는 소프트웨어 프로그램을 가지고 있었습니다. 그는 4개의 다른 색상으로 시작했습니다. 각각은 코딩된 염색체로 코딩되었습니다(그 데코ー디은그된 값은 RGB값이 된다). 소비자는 4가지 색 중 1개를 선택합니다(자신이 염두에 두고 있는 것으로 가장 가까운 색). 다음에 프로그램은 그 개인에 가장 적합성을 배정하고 돌연변이/크로스를 사용하고 다음 세대에 이동합니다. 소비자가 정확한 색깔을 찾을 때까지 상기의 스텝을 되풀이한 뒤 컬러의 사람이 RGB의 조합을 가르치는 데 사용됩니다!소비자가 염두에 두고 있는 색이 최대한 적합성을 줌으로써 color Guy의 프로그램은 소비자들이 정확하게 염두에 두고 있는 색이 수습할 가능성을 높이고 있습니다. 나는 꽤 웃겼어!이제 저는-1을 얻었습니다. 더 많은-1을 계획하고 있다면 pls. 그럴 이유를 설명하자!집을 페인트칠할 때 정확한 색상 조합을 얻는 것은 종종 어렵습니다. 대부분 염두에 두고 있는 색상이 있지만, 그 색상 중 하나가 아닌 경우는 벤더가 표시합니다.어제 GA 연구원인 제 교수님이 독일에서 있었던 실화에 대해 언급했습니다(죄송합니다.더 이상 참고할 자료가 없습니다. 네, 원하시는 분이 계시면 찾아드릴 수 있습니다). 이 사람(컬러의 사람이라고 합시다)은 사람들이 고객이 염두에 둔 것과 가장 유사한 정확한 컬러 코드(RGB)를 찾는 것을 돕기 위해 방문했습니다. 그의 방식은 다음과 같습니다.컬러 가이는 GA를 사용하는 소프트웨어 프로그램을 가지고 다녔습니다. 그는 4가지 다른 색으로 시작했습니다. 각각은 코딩된 염색체로 코딩되었습니다(그 디코딩된 값은 RGB 값이 됨). 소비자는 4가지 색상 중 하나를 선택합니다(자신이 염두에 두고 있는 것과 가장 가까운 색상). 그런 다음 프로그램은 해당 개인에게 최대 적합성을 할당하고 돌연변이/크로스를 사용하여 다음 세대로 이동합니다. 소비자가 정확한 색상을 찾을 때까지 위의 단계를 반복한 후 컬러의 사람이 RGB 조합을 알려주는 데 사용됩니다!소비자가 염두에 두고 있는 색상에 최대한의 적합성을 부여함으로써 color Guy의 프로그램은 소비자가 정확히 염두에 두고 있는 색상으로 수렴할 가능성을 높이고 있습니다. 나는 꽤 재미있었어!이제 저는 -1을 얻었습니다. 더 많은-1을 계획하고 있다면 pls. 그렇게 하는 이유를 밝혀라!제 논문의 일부로서 진화 개념을 사용하는 GA이며 다중 목표 최적화 알고리즘 mpOEMS(진화 개선 단계를 사용한 다중 목표 프로토 타입 최적화)을 위한 일반 Java프레임워크를 작성했습니다. 모든 문제의 독립 부분이 문제의 종속 부분으로 분리되어 있으며, 문제의 종속 부분만 추가하고 체제를 사용할 수 있도록 인터페이스가 제공된다는 점에서 일반적입니다. 그러므로 알고리즘을 사용하려는 사람은 처음부터 시작할 필요가 없어 작업을 꽤 쉽게 합니다.여기에 코드를 찾아낼 수 있습니다.이 알고리즘에서 찾을 수 있는 솔루션은 과학 작업에서 최첨단 알고리즘 SPEA-2및 NSGA과 비교되면서 다음의 사실이 입증되었습니다.알고리즘은 퍼포먼스를 측정하기 위해서 취하는 시학, 특히 찾고 최적화 문제에 응하고, 유사 또는 보다 좋은 퍼포먼스를 나타냅니다.여기에서 찾아볼 수 있습니다.또 논문 및 작업 증명의 일부로서 이 프레임워크를 포트폴리오 관리에서 발견되는 프로젝트 선택 문제에 적용했습니다. 회사에 가장 큰 가치를 더하거나 회사의 전략을 거의 지원하거나 기타 임의의 목표를 지원하는 프로젝트를 선택하는 것입니다. 예:특정 카테고리에서 특정의 수 프로젝트 선택 또는 프로젝트 시너지를 극대화…이 틀을 프로젝트 선택 문제에 적용한 내 논문:http://www.ub.tuwien.ac.at/dipl/2008/AC05038968.pdf그 후 나는 포천 500대 기업 중의 하나의 포트폴리오 관리 부서에서 일했습니다만, 그래서 그들은 프로젝트 선택 문제/포트폴리오 최적화에도 GA을 적용한 상용 소프트웨어를 사용했습니다. 추가 자원:프레임워크 문서:http://portal.acm.org/citation.cfm?id=1792634.1792653프레젠테이션 용지:http://thomaskremmel.com/mpoems/mpoems_in_java_documentation.pdfmPOEMS실제로 좀 정열이 있으면 누구나 일반 체제의 코드를 임의의 멀티 목표 최적화 문제에 쉽게적용할 수 있습니다.내 논문의 일부로 진화 개념을 사용하는 GA인 다중 목표 최적화 알고리즘 mPOEMS(진화 개선 단계를 사용한 다중 목표 프로토타입 최적화)를 위한 일반 자바 프레임워크를 만들었습니다. 모든 문제의 독립 부분이 문제의 종속 부분과 분리되어 있고 문제의 종속 부분만 추가하여 프레임워크를 사용할 수 있도록 인터페이스가 제공된다는 점에서 일반적입니다. 따라서 알고리즘을 사용하려는 사람은 제로부터 시작할 필요가 없어 작업을 상당히 쉽게 합니다.여기서 코드를 찾을 수 있습니다.이 알고리즘에서 찾을 수 있는 솔루션은 과학 작업에서 최첨단 알고리즘 SPEA-2 및 NSGA와 비교되어 다음과 같이 증명되었습니다.알고리즘은 성능을 측정하기 위해 취하는 메트릭, 특히 찾고 있는 최적화 문제에 따라 유사하거나 더 나은 성능을 나타냅니다.여기서 찾을 수 있어요.또한 논문 및 작업 증명의 일부로서 이 프레임워크를 포트폴리오 관리에서 발견되는 프로젝트 선택 문제에 적용했습니다. 회사에 가장 큰 가치를 더하거나 회사의 전략을 대부분 지원하거나 기타 임의의 목표를 지원하는 프로젝트를 선택하는 것입니다. 예: 특정 범주에서 특정 수의 프로젝트 선택 또는 프로젝트 시너지 극대화…이 틀을 프로젝트 선택 문제에 적용한 나의 논문:http://www.ub.tuwien.ac.at/dipl/2008/AC05038968.pdf그 후 나는 포천 500대 기업 중의 하나의 포트폴리오 관리 부서에서 일했습니다만, 그래서 그들은 프로젝트 선택 문제/포트폴리오 최적화에도 GA을 적용한 상용 소프트웨어를 사용했습니다. 추가 자원:프레임워크 문서:http://portal.acm.org/citation.cfm?id=1792634.1792653프레젠테이션 용지:http://thomaskremmel.com/mpoems/mpoems_in_java_documentation.pdfmPOEMS실제로 좀 정열이 있으면 누구나 일반 체제의 코드를 임의의 멀티 목표 최적화 문제에 쉽게적용 가능합니다.저는 식량원과 광산의 랜덤 그리드 지형 세트에 의한 로봇 탐색의 멀티 쓰레드 스윙 기반 시뮬레이션을 개발하고 로봇 행동의 최적화와 로봇 염색체에 대한 최적의 유전자의 생존을 탐구하는 유전자 알고리즘 기반 전략을 개발했습니다. 이는 각 반복 주기 차트와 매핑을 사용하여 수행되었습니다.그 이후로 저는 더 많은 게임 행동을 개발했습니다. 내가 최근 직접 구축한 예제 어플리케이션은 시작 및 목표 상태는 물론 1개/다중 접속 지점, 지연, 취소, 건설 작업, 러시 아워, 공개 파업, 가장 빠른 경로로 가장 싼 경로 사이의 고려. 다음에 특정 날짜로 루트의 균형 잡힌 권장 사항을 제공합니다.일반적으로 저의 전략은 POJO베이스의 유전자 표현을 사용한 후 선택, 돌연변이, 교차 전략 및 기준 포인트에 대한 특정 인터페이스 구현을 적용하는 것입니다. 하면 저의 피트니스 기능은 기본적으로 내가 발견적 측정으로 적용해야 할 전략과 기준에 의해서 상당히 복잡하게 됩니다.또 알고리즘이 논리를 이해하고, 코드 수정의 권장 사항을 포함한 버그 리포트를 확인하려는 체계적인 돌연변이 사이클을 사용하여 코드 내의 자동화 테스트에 유전 알고리즘을 적용하는 방법을 검토했습니다. 기본적으로는 자신의 코드를 최적화하고 개선하기 위한 권장 사항을 제공하는 방법과 새로운 프로그래밍 방식 코드 검색을 자동화하는 방법입니다. 나는 또 다른 애플리케이션에서 음악 제작에 유전 알고리즘을 적용하려고 시도했습니다.일반적으로 대부분의 메타 휴리스틱/글로벌 최적화 전략처럼 진화 전략을 찾습니다. 처음에는 학습 속도가 느리지만 솔루션이 목표 상태에 점점 다가오면서 적합성 기능과 휴리스틱이 잘 정렬되며 검색 공간 내에서 그 수습.나는 식량원과 광산의 랜덤 그리드 지형 세트를 통한 로봇 탐색의 멀티 스레드 스윙 기반 시뮬레이션을 개발하고 로봇 행동 최적화와 로봇 염색체에 대한 최적의 유전자 생존을 탐구하는 유전자 알고리즘 기반 전략을 개발했습니다. 이것은 각 반복 사이클의 차트와 매핑을 사용하여 수행되었습니다.그 이후로 저는 더 많은 게임 행동을 개발해 왔습니다. 내가 최근에 직접 구축한 예제 애플리케이션은 시작 및 목표 상태는 물론 1개/다중접속 지점, 지연, 취소, 건설 작업, 러시아워, 공개 파업, 가장 빠른 경로와 가장 저렴한 경로 사이의 고려. 그런 다음 특정 날짜에 취할 루트의 균형 잡힌 권장 사항을 제공합니다.일반적으로 나의 전략은 POJO 기반 유전자 표현을 사용한 후 선택, 돌연변이, 교차 전략 및 기준점에 대한 특정 인터페이스 구현을 적용하는 것입니다. 그러면 나의 피트니스 기능은 기본적으로 내가 발견적 측정으로 적용해야 하는 전략과 기준에 따라 상당히 복잡해집니다.또한 알고리즘이 논리를 이해하고 코드 수정 권장 사항을 포함하는 버그 리포트를 확인하고자 하는 체계적인 돌연변이 사이클을 사용하여 코드 내 자동화 테스트에 유전 알고리즘을 적용하는 방법을 검토했습니다. 기본적으로 자신의 코드를 최적화하고 개선하기 위한 권장 사항을 제공하는 방법과 새로운 프로그래밍 방식 코드 검색을 자동화하는 방법입니다. 나는 또한 다른 애플리케이션 중 음악 제작에 유전 알고리즘을 적용하려고 시도했습니다.일반적으로 대부분의 메타휴리스틱/글로벌 최적화 전략과 같은 진화 전략을 찾습니다. 처음에는 학습 속도가 느리지만 솔루션이 목표 상태에 점점 가까워지고 적합성 기능과 휴리스틱이 잘 정렬되어 검색 공간 내에서 그 수렴.학부 논문 때문에 유전 프로그래밍을 사용하고 항공 수색과 구조에 사용하는 협력 수사 전략을 개발했습니다. 저는 NetLogo(StarLogo기반)라는 오픈 소스 에이전트 모델링 플랫폼을 월드 모델로 사용하셨습니다. NetLogo는 Java로 작성되며 Java API을 제공합니다. 그러므로 GP프레임워크는 Java를 기반으로 해야 합니다. 제가 쓴 것은 JGAP는 Java에는 ECJ라는 또 하나의 오픈 소스 GP프레임워크가 있습니다.시뮬레이션은 실행 속도가 매우 늦었기 때문(NetLogo모델 때문이라고 생각합니다)기능/터미널 세트가 상당히 제한되면서 검색 공간이 제한되었습니다. 그럼에도 불구하고 몇가지 좋은 솔루션을 떠올랐어요. 충동을 느끼면 나의 논문 3장에서 볼 수 있습니다.http://www.cse.unsw.edu.au/~ekjo014/z3157867_Thesis.pdf학부 논문을 위해 유전 프로그래밍을 사용하여 항공 수색과 구조에 사용하는 협력 수색 전략을 개발했습니다. 나는 NetLogo(Star Logo 기반)라는 오픈 소스 에이전트 모델링 플랫폼을 월드 모델로 사용했습니다. NetLogo는 Java에서 작성되며 Java API를 제공합니다. 따라서 GP 프레임워크는 Java를 기반으로 해야 합니다. 제가 사용한 것은 JGAP라고 하고 자바에는 ECJ라는 또 다른 오픈 소스 GP 프레임워크가 있습니다.시뮬레이션은 실행 속도가 매우 느려서(Net Logo 모델 때문인 것 같습니다) 기능/터미널 세트가 상당히 제한되고 검색 공간이 제한되었습니다. 그럼에도 불구하고 몇 가지 좋은 솔루션을 생각해 냈습니다. 충동을 느끼면 제 논문 3장부터 읽을 수 있어요.http://www.cse.unsw.edu.au/~ekjo014/z3157867_Thesis.pdf